
[Computer Vision] Self-Supervised Learning 톺아보기 ; VICReg

저자인 Yann LeCun을 보면 알 수 있듯이 Facebook AI Research (FAIR)에서 작성해 ICLR 2022에 accept된 논문이다.
논문 링크는 아래에 있다.
이번 포스트에서는 이전의 Self-Supervised Learning(SSL)의 방법론과는 다르게 Simple하고 Explicit한 Regularization term으로 좋은 performance를 보인 VICReg에 대해 설명해보겠다.
요약
- Invariance term으로 image의 differen view의 invariance를 학습하고
- Variance preservation term으로 representation의 collapse를 피하고
- Covariance regularization term으로 embedding vector의 information을 최대화하면
- 복잡한 technique이나 Negative sample 없이도 SOTA 성능을 보이고 Multi-modal task에 적합한 SSL approach 완성!
Introduction
Self-supervised learning의 main challenge는 input image와 상관없이 embedding vector가 동일한 output으로 나오는 Collapse 문제이다.
이를 해결하기 위한 방법론으로는 대표적으로 3가지가 있다.
- Contrastive method (SimCLR,MoCo), Clustering method (DeepCluster, SwAV)와 같이 수많은 negative sample을 활용하는 방법.
- Distillation method (BYOL, SimSiam)와 같이 teacher-student network 방식으로 Momentum encoder, Stop gradient, Predictor와 같은 techniuqe을 활용해 asymmetric network architecture를 만드는 방법
- Information maximization method (Barlow Twins, W-MSE)와 같이 embedding vector를 decorrelation 시켜 information collapse 방지를 하는 방법
이번에 리뷰하게 된 VICReg은 Information maximization method에 속한다.
이전 모델들인 Whitening MSE와 Barlow Twins는 다른 Post에서 확인할 수 있다!
Intuition
가장 기본적인 VICReg의 아이디어는 이름에서 알 수 있듯이 Variance-Invariance-Covariance이다.
이에 대한 각각의 정의를 저자는 다음과 같이 설명하고 있다.
- Variance : a hinge loss to maintain the standard deviation (over a batch) of each variable of the embedding above a given threshold. This term forces the embedding vectors of samples within a batch to be different.
- Invariance : the mean square distance between the embedding vectors.
- Covariance : a term that attracts the covariances (over a batch) between every pair of (centered) embedding variables towards zero. This term decorrelates the variables of each embedding and prevents an informational collapse in which the variables would vary together or be highly correlated.
뒤에서 자세히 설명하겠지만 간단히 말하면 동일한 image들은 비슷한 embedding vector value를 갖도록 (Invariance), embedding vector이 0으로 collapse 되지 않도록 (Variance), embedding vector의 variable 간의 redundancy를 줄여 informational colaapse를 막도록 (Covariance) 하는 Term들이다.
특히나 Variance와 Covariance는 각각의 branch network에 적용된다는게 중요한 특징이다.
이를 통해서 VICReg은 이전의 방법론들에 비해
- 두개의 branch network들이 weight sharing을 하거나 동일한 network architecture를 가질 필요가 없다.
- Negative sample이 필요없기 때문에 큰 용량의 memory bank나 large batch size가 필요가 없다.
- Batch-wise normalization이나 feature-wise normalization이 필요가 없다.
- Vector quantization나 predictor module이 필요가 없다.
Method
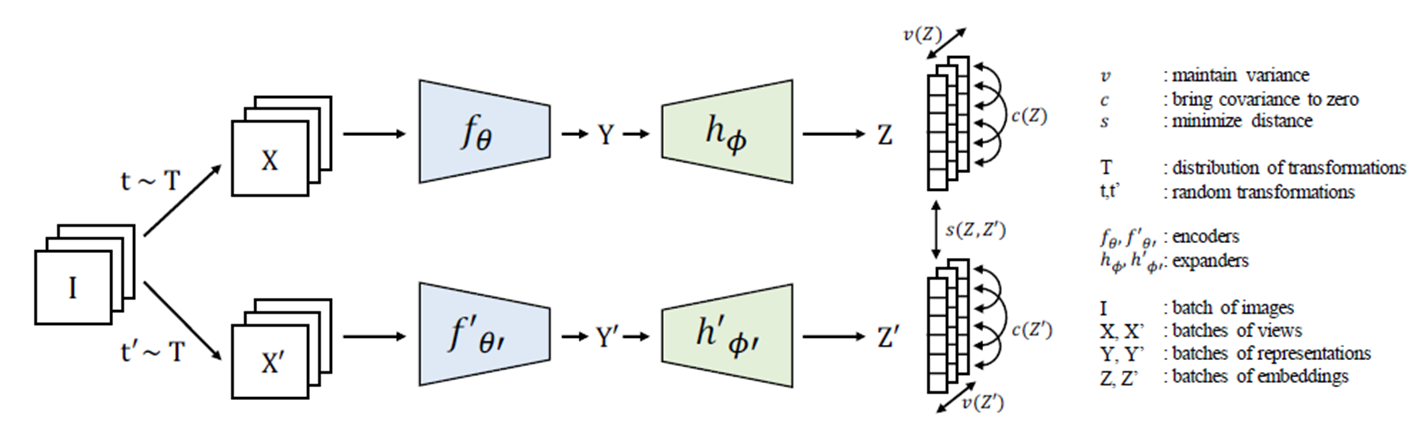
위의 figure가 VICReg의 전체적인 구조이다. joint embedding architecture로 input image가 서로 다른 transformation을 거쳐 encoder, expander를 거쳐 embedding vector를 뽑아내고 이에 대해 variance (v), covariance (c), invariance (s) term을 산출한다.
물론 각 branch network의 architecture는 동일할 필요가 없으나 이 논문을 위한 대부분의 실험에서는 동일한 network, weight sharing을 적용했다. Encoder는 ResNet-50 backbone을 사용하였고 output dimension은 2048, expander는 size 8192의 3 fully-connected layer를 사용했다.
이제 이 논문의 핵심이라고 볼 수 있는 각각의 term에 대해 자세히 살펴보겠다.
1. Variance Preservation term
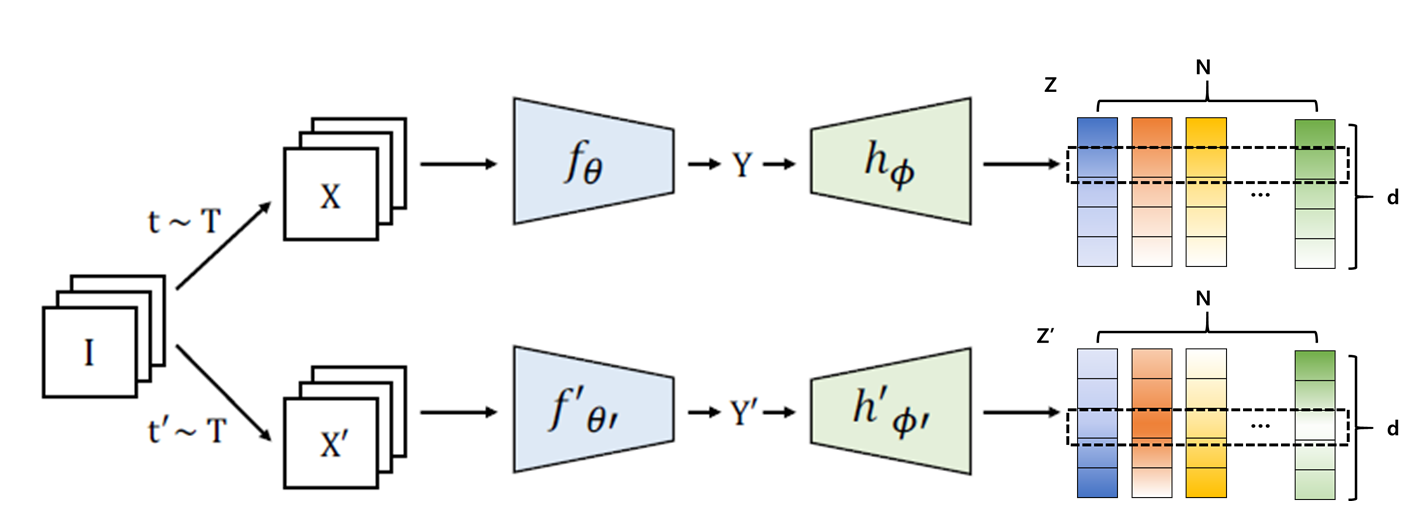
우선 expander까지 통과한 embedding vector Z와 Z’은 N by d dimension을 가진다. N은 input image의 batch-size, d는 embedding vector의 dimension size이다.
Variance Preservation term은 embedding vector의 각 dimension이 특정 값 이상의 variance를 강제로 가지도록 하여 모든 iput에 대해 동일한 embedding vector를 만들어내는 collapse를 방지하기 위한 term이다. 위의 그림처럼 검은 점선 네모로 표현된 부분의 dimension 값들이 동일한 값이 아닌 variance를 일정 수준 이상으로 유지하는 것이 목적이다.
즉, Embedding vector의 N개의 j번째 dimension 값들의 standard deviation이 $\gamma$ 이상이 되도록 학습시켜 모든 input이 같은 embedding vector로 mapping되는 collapse를 방지하는 것이 목적인 term이다. 때문에 이는 SVM에서 사용되는 loss인 hinge loss 형태로 다음과 같이 표현된다.
여기서 $\epsilon$은 학습과정에서 numerical stability를 위해 더해주는 작은 scalar value (0.0001)이고 $\gamma$는 1로 설정했다.
이 때 variance 대신 standard deviation 값을 사용한 이유는 $Var(x)$의 gradient가 정의상 $x$가 $x$의 평균인 $\overline{x}$에 가까워지는 경우 gradient가 0에 가까워지고 이는 결국 학습이 되지 않아 collapse가 일어날 가능성이 커지기 때문이다.
여기서 주목해야할 점은 이 variance term은 각각의 branch에서 따로 구해진다는 것이다.
2. Covariance Regularization term
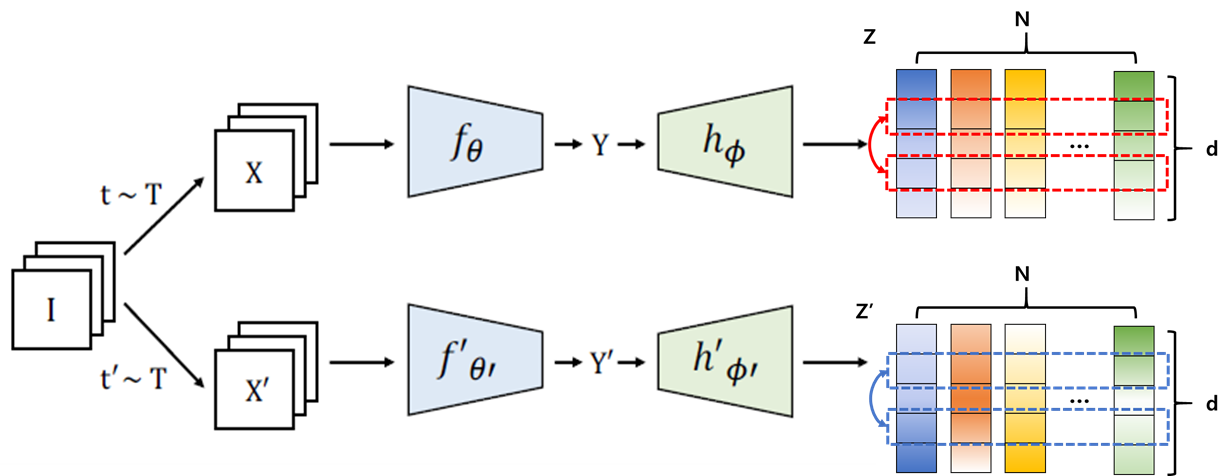
다음은 Covariance Regularization term이다.
저자도 이 부분은 Barlow twins에게서 영감을 받았다고 한다.
중요한 차이점은 Barlow twins에서 구한 것은 서로 다른 branch에서 나온 embedding인 Z와 Z’의 cross-correlation을 구했다면, VICReg의 Covariance Regularization term에서는 각각의 branch에서 나온 embedding 내에서 covariance를 구한다는 점이다.
위의 그림에서 보다시피 위쪽 branch에서 나온 embedding vector Z에서 빨간색 점선 네모로 표시한 것처럼 dimension 끼리의 covariance를 구하고 아래쪽도 동일한 방식으로 covariance를 구한다. 그렇게 각 dimension 사이의 covariance를 담고 있는 Covariance Matrix를 구한다. 이 때 Variance preservation term과 같이 branch마다 각각 계산된다는 점을 잘 기억하자.
Covariance matrix를 의미하는 수식을 살펴보면 다음과 같다.
Covariance matrix에서 우리에게 중요한 것은 off-diagnoal coefficient이다. Diagonal coefficient는 당연하게도 자기 자신과의 covariance 이므로 1이 될 것이고 그 외의 다른 dimension 사이의 covariance는 0에 가까워질수록 서로 관련이 없는 정보를 encoding한다고 할 수 있다. 그렇기 때문에 $C(z)$의 off-diagonal coefficient들만 모은 것을 covriance regularization term이라고 하고 다음과 같이 나타낸다.
이 $c(Z)$를 작게 만들수록 embedding vector의 dimensoin 사이의 decorrelation이 커질 것이고 이는 유사한 정보를 encoding하게 되는 informational collapse를 방지할 수 있게 될 것이다.
3. Invariance term
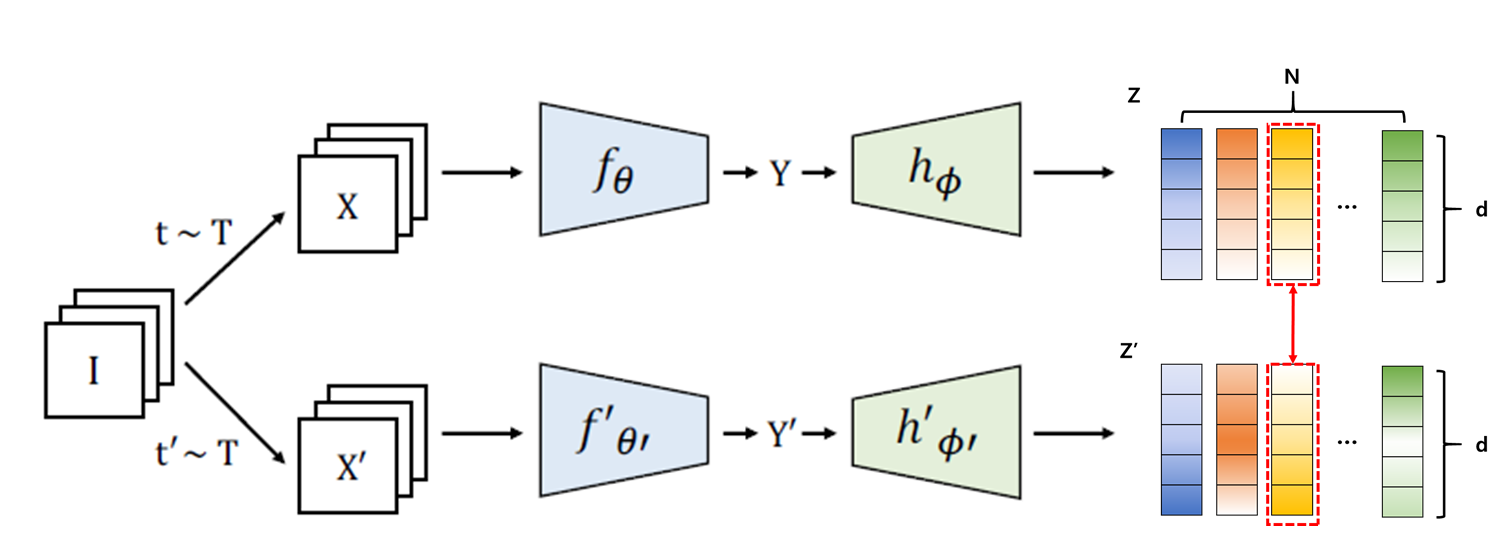
마지막으로 Invariance term이다. 이는 Self-supervised Learning에서는 굉장히 익숙한 개념이다.
위의 그림과 같이 동일한 image로부터 나온 sample들의 embedding vector 사이의 거리를 의미하는 term이며 이를 수식으로 표현하면 아래와 같다.
Embedding vector $Z와 Z’$ 사이의 mean-squared euclidean distance로 표현되고 있다.
만일 이 term만 loss로 사용하여 학습한다면 모든 embedding vector가 동일해져 우리가 우려했던 collapse가 일어날 것이다. 그렇기 때문에 해당 논문에서 추가적인 variance와 covariance term을 반영한 것이다.
그럼 지금까지 살펴본 term들을 종합해 loss function $l$을 구성해보자.
ㅍ 수식을 보면 알 수 있듯이 invariance term은 두 개의 branch network로 부터 하나의 term만 나오고 variance term과 covariance term은 각각의 embedding vector Z와 Z’ 각각에서 나오기 때문에 이 둘의 합으로 이루어져있다.
여기서 $\lambda, \mu, \nu$는 hyper-parameter로 $\nu=1$로 setting하고 나머지 $\lambda$와 $\mu$는 같고 1보다 크다는 조건하에 grid search를 진행했다. 그 결과 $\lambda$와 $\mu$는 25일 때 가장 좋은 성능을 보였다.
그리고 이 loss function을 unlabelled dataset $D$의 모든 이미지에 대해 구한 overall objective function은 아래와 같다.
$Z^I,Z’^I$는 unlabelled dataset의 subset인 image batch $I$에 $t$와 $t’$ transformation을 한 뒤 구한 embedding vector들 이다.
당연하게도 이 objective function을 minimize하는 encoder parameter $\theta$와 expander parameter $\phi$를 구하기 위한 학습을 진행하면 마무리된다.
Results
우선 VICReg의 pretraining은 ImageNet dataset에서 label을 제외하고 진행했으며 이 후 performance evaluation은 expander를 제거하고 새로운 layer를 이어 붙여 진행하였다.
1. Evaluation on ImageNet
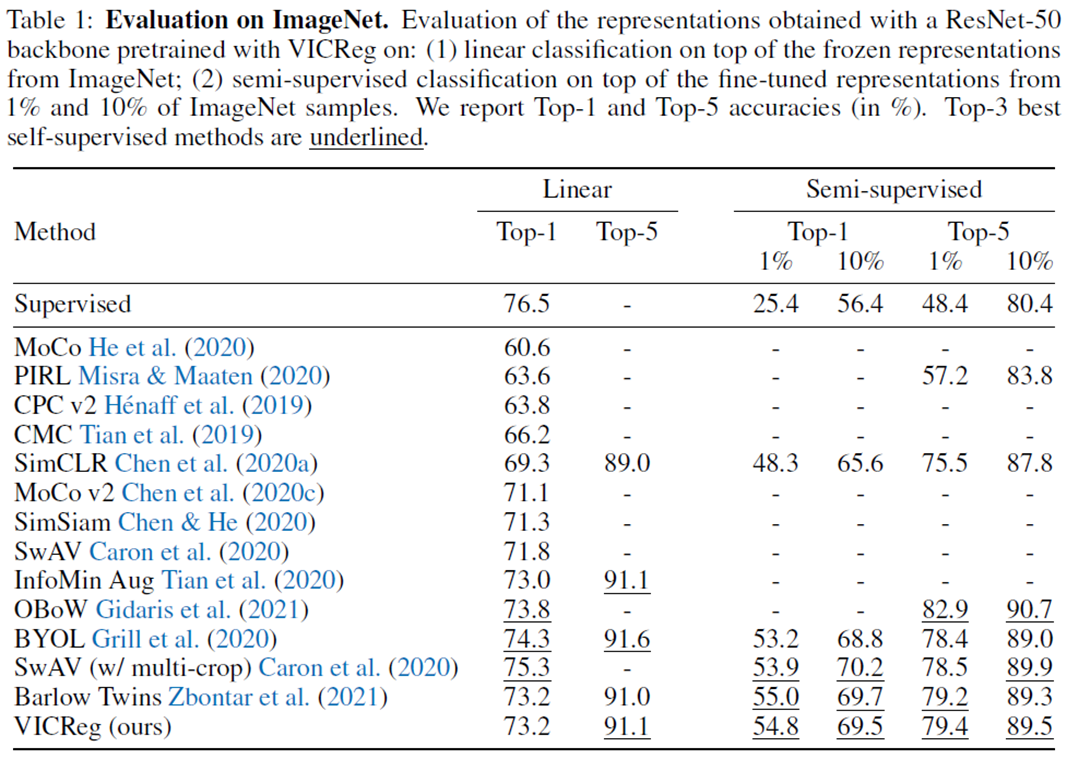
첫 번째 실험은 ImageNet에 대해 진행한 실험이다. ImageNet dataset의 test set으로 성능을 측정하였으므로 pretraining한 dataset과 evaluation하는 dataset의 domain이 동일하다고 볼 수 있다.
위 표의 Linear라고 써있는 결과는 VICReg을 통해 학습한 ResNet-50 backbone (encoder)의 weight를 frozen하고 뒤에 이어붙인 linear classfier만 imageNet dataset으로 학습시켜 성능을 평가한다. 그 옆의 Semi-supervised setting은 1% 또는 10%의 training set을 가지고 VICReg을 통해 학습한 ResNet-50 backbone의 weight까지도 fine-tune한다다. 이는 현실에서 unlabelled data가 더 많은 상황에서 일부 labelled data를 활용해 성능을 끌어올릴 수 있는지 확인하는 실험 세팅이다.
결과를 보면 VICReg은 다른 SOTA 알고리즘과 비교해 유사한 성능을 보인다다. 특히나 Barlow Twins와 굉장히 유사한 성능을 보이고 있는데 거기에 더해 objective function의 modularity가 높다는 점과 multi-modal setup으로 확장 가능하다는 것이 주요 장점이라고 저자는 주장한다. 특히나 linear evaluation setting에서 worse run과 best run의 정확도가 0.1% 차이밖에 안나 매우 안정적인 알고리즘으로 볼 수 있다.
2. Transfer to other downstream tasks
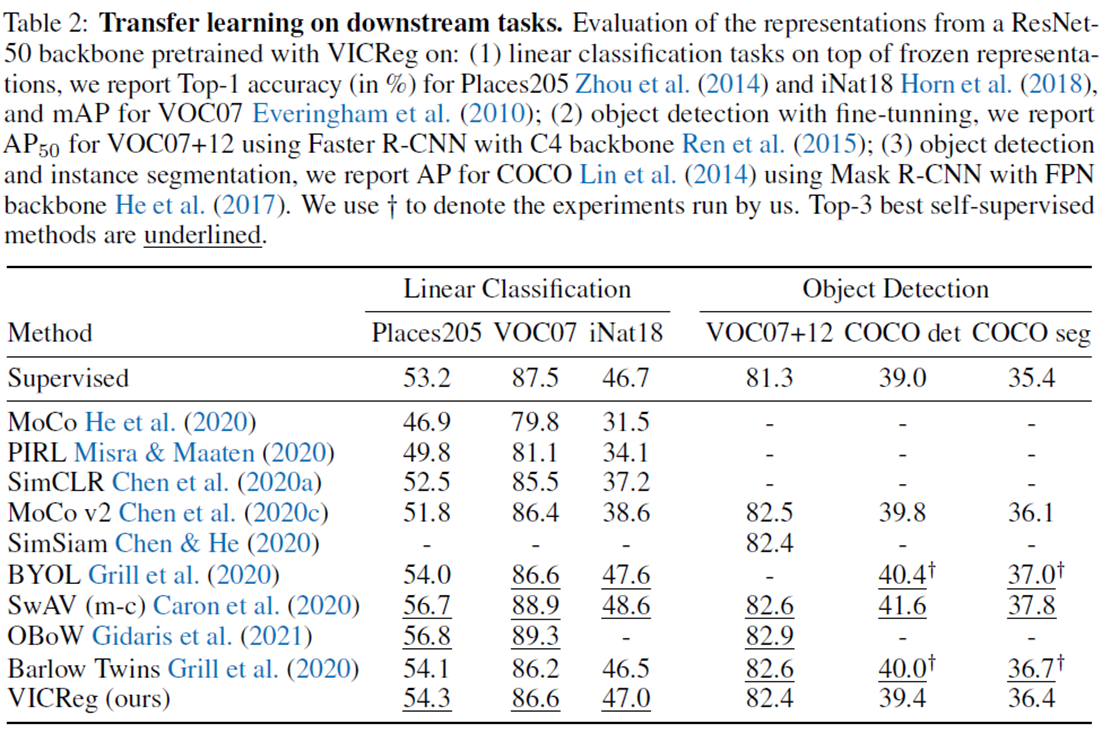
두 번째 실험은 학습된 dataset과 다른 dataset에 대해서 transfer learning을 적용했을 때 성능평가를 진행했다.
Linear classification setting에서는 scene classifcation datset인 Place205, multi-label image classification dataset인 VOC07, fine-grained image classification dataset인 iNaturalist2018을 사용하였다.
그러고는 아예 dataset뿐만 아닌 task 자체를 object detection으로 바꾸어 실험을 진행했다.
그 결과는 표에서 볼 수 있듯이 classification에서는 준수하지만 detection task에서는 약간 기대에 못 미치는 모습을 보인다.
3. Multi-modal pretraining on MS-COCO
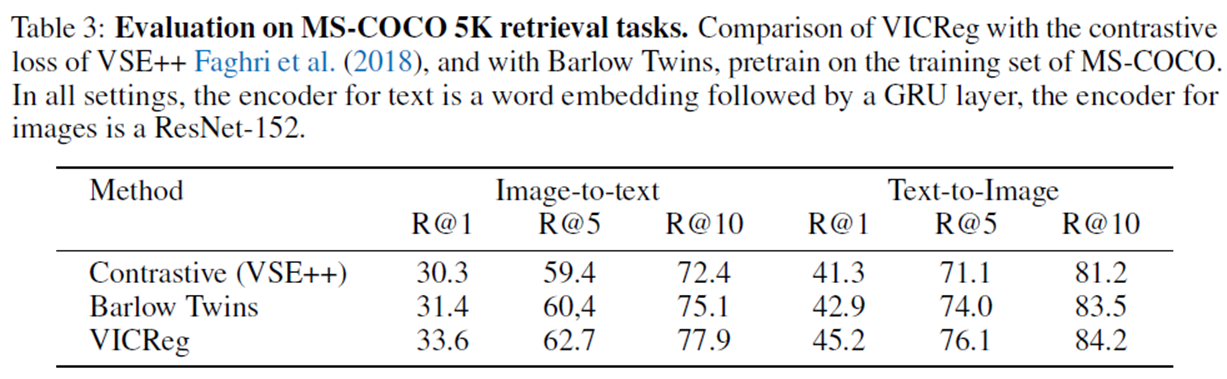
VICReg와 Barlow Twins의 가장 큰 차임저은 각각의 branch를 독립적으로 regularization 한다는 점이다. 이로 인해 VICReg은 각각의 branch가 완전히 다른 종류의 network architecture를 가지거나 다른 data type을 처리하는 것이 가능해진다.
그렇기에 저자는 VICReg의 Multi-modal 성능을 보여주기 위해 MS-COCO dataset을 통해 retrieval task를 수행한 결과를 위의 표로 정리했다. MS-COCO dataset은 image와 그에 대한 caption이 pair로 이루어진 dataset이며 이를 통해 pretrain한 뒤 성능을 측정하였다. Self-supervised learning 알고리즘 중 이렇게 data type이 다른 경우 활용할 수 있는 Barlow twins와 Vse++를 대조군으로 사용했다.
그 결과 Image-to-Text, Text-to-Image retrieval task 모두 VICReg이 큰 격차로 높은 성능을 보였다. 저자가 계속해서 강조해온 multi-modality performance를 확인할 수 있는 가장 중요한 실험 결과라고 볼 수 있다.
Analysis
이 section에서는 VICReg의 component가 성능에 어떤 영향을 미치고 서로 상호작용하는지, 그리고 이전의 방법론들에 사용된 technique들과 어떤 관계인지 분석하고 있다.
1. Asymmetric networks
SOTA 성능을 나타내고 있는 Distillation method인 BYOL이나 SimSiam의 경우 batch normalization, predictor, stop gradient, momentum encoder와 같이 의도적으로 asymmetric network를 만드는 technique을 사용해 성능을 효과적으로 끌어올렸다.
그리고 마지막에 invariance loss function 만을 사용해 학습을 진행했다.
반면 VICReg은 어떠한 technique도 사용하지 않았고 그 대신 variance와 covariance term을 사용하고 있다. 그러므로 이는 위에서 언급한 technique들과 variance, covariance term이 어떠한 연관성을 가지는지 실험적으로 확인해볼 수 있다.
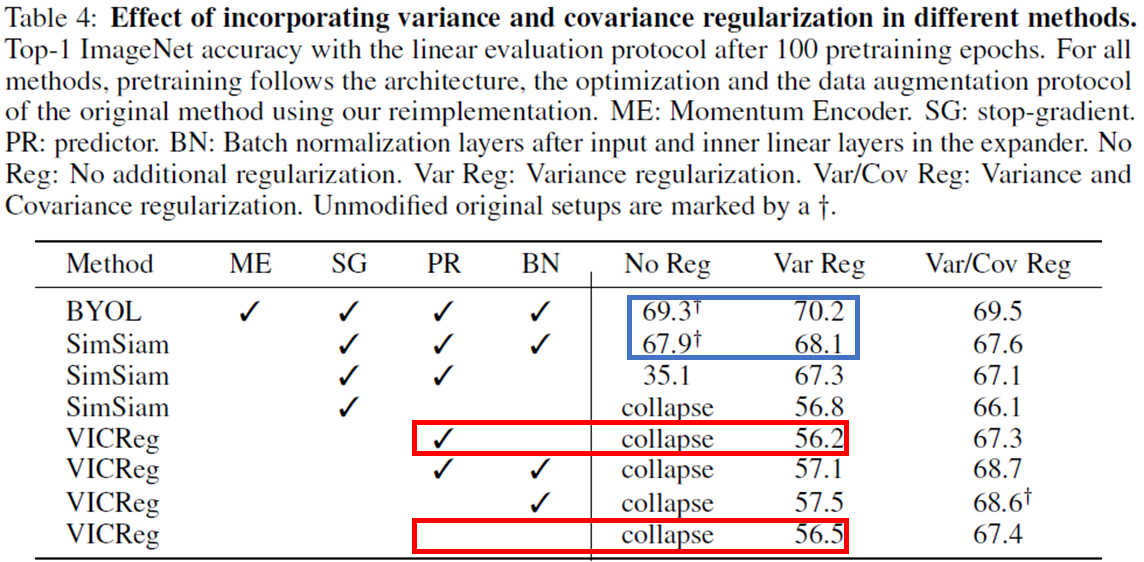
이를 정리한 실험 결과가 위의 표이다.
특히 VICReg의 핵심이라고 볼 수 있는 Variance term에 대한 실험이 주로 실행되었다. Variance term을 사용할 때 Predictor를 추가하는 것과 그렇지 않은 것은 성능에 차이를 일으키지 않았습니다. (56.2% vs 56.5%) 그 때문에 Predictor는 Variance term에 redundant함을 알 수 있다. SimSiam에서 Batch normalization의 유무에 따라 성능이 크게 차이나는 것 (35.1% -> 67.9%) 과는 대조적으로 VICReg에서 expander에 Batch normalization을 추가한 경우 1%의 성능 향상만을 보이고 있어 Variance term이 Batch Normalizatoin 역할을 어느정도 해주고 있음을 알 수 있다.
다음으로 Variance term과 Stop gradient (SG)나 Momentum encoder (ME)를 사용했을 때 각각 0.2%, 0.9%의 성능향상을 보여주는데 이는 SG나 ME만으로 완벽히 embedding vector의 variance를 유지하지는 못한다는 것으로 해석할 수 있다.
2. Weight sharing
앞 section에서는 asymmetric network를 만드는 technique들과 VICReg의 term간의 관계를 살펴보았다. 이번에는 Weight sharing 여부, 그리고 한발 더 나아가 different architecture로 구성될 경우 VICReg의 Robustness를 확인하는 실험을 진행하였다.
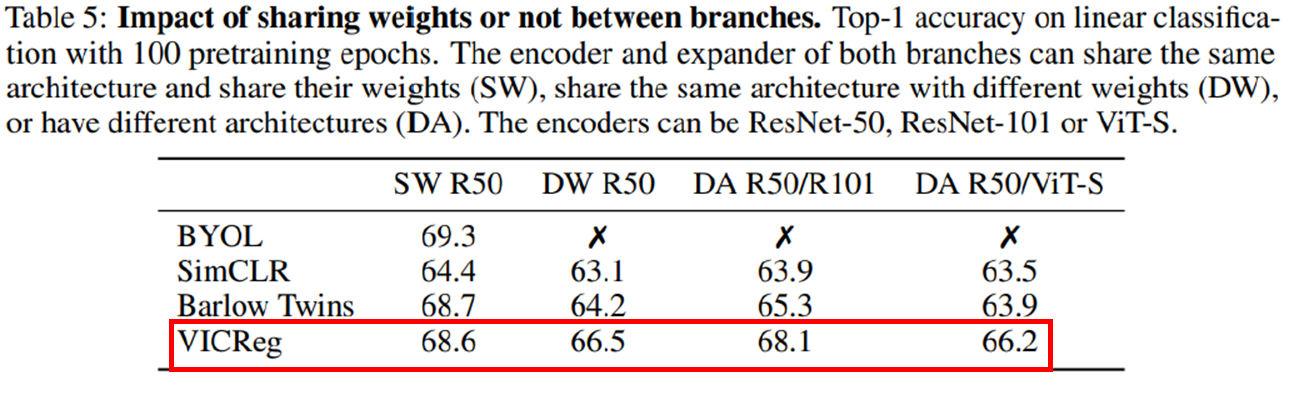
실험은 Weight sharing (SW), not shared (DW), encoder가 different architecture (DA)인 시나리오로 나누어 진행하였다. 또한 이러한 시나리오가 가능한 알고리즘은 SimCLR, Barlow Twins이기 때문에 이들과 성능을 비교하였다.
Weight sharing을 한 시나리오에서 모든 알고리즘이 가장 높은 성능을 보였고 DW, DA에서 성능이 감소함을 확인할 수 있는데 그 감소폭이 다른 알고리즘에 비해 VICReg이 가장 작음을 확인할 수 있다.
이는 VICReg이 다른 weight, architecture에서 가장 robust한 성능 유지를 보여준다는 의미이며 이 덕분에 input modality를 가지고 multi-modal과 같은 다양한 application에 적합한 모델임을 의미한다.
Conclusion
결론! VICReg은 invariance, variance, covariance term을 사용한 simple approach로 이걸로도 SOTA 성능을 다양한 task에서 보였고 embedding branch가 동일하거나 비슷할 필요도 없기 때문에 이 전 method들이 가지는 한계점이 보이지 않는다!!!
댓글남기기