
[Computer Vision] Object Detection 톺아보기-1 ; R-CNN

2012년 ILSVRC에서부터 CNN은 image classification에서 큰 성능 향상을 나타내고 있었고
CVPR 2014에서 마침내 CNN을 활용한 object detection의 시초격인 R-CNN (Regions with CNN features)이 발표되었다.
이번 포스트에서는 이를 요약 정리해보며 object detection 톺아보기를 시작하려한다.
요약
- R-CNN을 통해 PASCAL VOC dataset에서 대해 이전 sota보다 30% 상승한 53.3%의 mAP 기록
- R-CNN은 Image classification으로 학습된 high-capacity CNN인 AlexNet을 fine-tuning
- Region proposal -> CNN -> SVM & Bounding box regression 로 3개의 module로 구성된 모델
- 향후 Fast R-CNN, Faster R-CNN, Mask R-CNN 계열의 2 stage detector의 뿌리가 됨.
Introduction
- Object detection에는 SIFT, HOG, Neocognition 등의 다양한 시도가 있었으나 성능이 답보된 상황
- CNN이 image classification에서 보여준 성능을 object detection으로 확장시키고자 함.
- 이를 위해서는 두 가지 문제; object localization, Insufficient labeled data 를 해결해야함.
- Object localization 해결을 위해 Region proposal을 사용하고 Insufficient labeled data 해결을 위해 fine-tuning을 사용.
Object detection with R-CNN
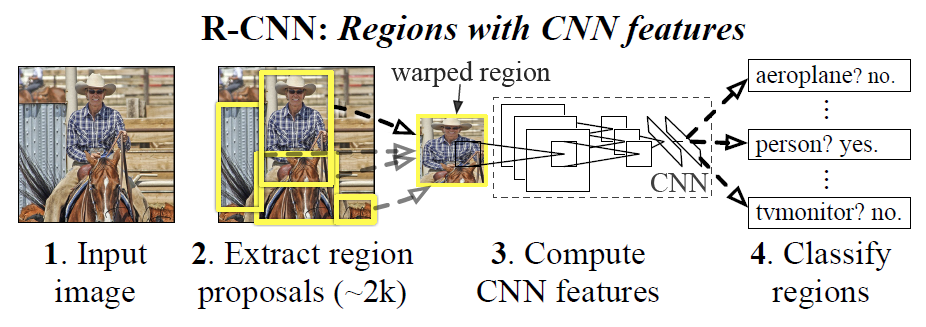
- 위의 그림처럼 3가지 module ; category-independent region proposal, CNN, SVM 으로 구성.
- Input image에서 2000개의 region proposal을 생성하고 이를 CNN을 통해 feature extraction 한 뒤 SVM을 통해 classfication.
1. Module design
- Region Proposal ; Selective Search algorithm 사용.

- 여러 region을 형성한 뒤 각 region과 유사성(color, texture, size, fill)이 높은 영역을 결합해 region proposal을 만드는 알고리즘.
- Feature extraction ; Krizhevsky et al.의 AlexNet 사용.
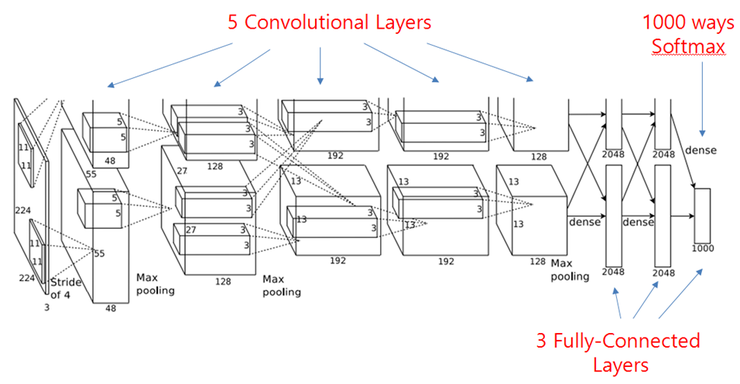
- 227 x 227 RGB image를 input으로 5 convolutional layer를 거쳐 4096-dimensional feature vector를 extraction

- Region proposal을 227x227 RGB image로 만들기 위해 context padding (16 pixel) 후에 warp를 시행 (위 사진의 column D, bottom low).
- Bound box regression

- Bound box regression은 selective search로 찾은 regional proposal이 더 정확한 object를 감쌀 수 있도록 하는 모델이다.
- P는 selective search로 찾는 (x 좌표, y 좌표, width, height)이고 G는 ground truth box이다.
- 간단히 말하자면 P를 G에 가깝게 만들어주는 w* parameter를 ridge regression을 통해 학습하는 것이다. 자세한 내용은 Appendix C를 참고.
2. Test-time detection
- Test 시에 한 image에서 나온 2000개의 regional proposal이 CNN-SVM을 거쳐 각각 (해당 region proposal이 어느 obejct class에 해당하는지) score가 산출된다.
- 하지만 이 모든 regional proposal 모두 의미있지 않을 것이다. 즉, 동일한 object를 가리키는 region proposal들이 있을 것이다.
- 이를 해결하기 위해 Non-maximum suppression 을 각각의 object class 마다 적용한다.
- Non-maixum suppression은 높은 score를 받은 region과 서로 겹치는 부분 (Intersection-over-union; IoU)이 threshold 이상이라면 같은 object를 지칭하는 Region으로 생각하고 제거하여 가장 적합한 region만 남기는 작업이다.

- 위 사진처럼 얼굴이라는 object class를 지칭하는 하나의 빨간 선으로 이루어진 region만 남기는 작업이다.
- Run-time analysis 결과 모든 category에 대해 동일한 CNN forward propagation을 하며 CNN feature vector가 4k dimension 정도로 낮아 기존의 detection system 보다 효율적이라고 주장한다.
3. Training
- Superviesed pre-training : ILSVRC 2012 classficiation에서 사용된 pre-trained AlexNet을 가져오겠다.
- Domain-specific fine-tuning : Object detetction dataset인 VOC (class ; 20개)와 ILSVRC 2013 (class ; 200개)로 기존의 CNN을 fine-tuning 한다.
- 이 때 헷갈렸던 점은 R-CNN에서 classifier는 SVM이기 때문에 end-to-end로 classifier까지 학습하는게 아니라 이 fine-tuning 단계에서 CNN parameter만 fine-tuning이 진행된다.
- 그렇기 때문에 이 때 fine-tuning에서만 사용할 (class 개수 plus 1 for background)-way classification softmax layer를 만들어 학습한다.
- Region proposal이 ground-truth box와 IoU 0.5 이상일 경우 Positive sample, 즉 정답으로 간주하고 그 외에는 Negative sample, 즉 background class로 예측하도록 학습한다.
- Optimizer (SGD), Learning rate (0.001),Mini-batch size (128 windows = 32 positive sample + 96 negative sample)
- Object category classifier
- CNN에 대한 fine-tuning 이후에 softmax가 아닌 SVM classfier을 만들어 따로 학습하는 과정을 거친다. 그리고 이 때 fine-tuning과 다른 점은 positive sample로 ground-truth box (IoU=1), negative sample은 IoU<0.3인 region만 고려한다는 점이다.
- 왜 그랬냐는 해답은 간편하다. 그게 더 성능이 잘 나왔으니까!
- 하지만 왜 이러한 세팅에서 성능이 더 잘 나왔는가에 대한 이유를 생각해봐야한다. 이를 저자는 Appendix B에 서술하였다.
- 저는 일단 가장 근본적인 원인은 당시 object detection data의 불충분함이라고 설명한다.
- data 양이 적으니 CNN을 fine-tuning할 때는 jittered example (IoU가 0.5에서 1 사이로 fine-tuning에서는 positive, SVM training에서는 ignored sample)들로 data 양을 늘려 overfitting을 방지해야했다.
- 히지만 IoU가 0.5에서 1 사이이기 때문에 정확한 localization은 어렵도록 fine-tuning 되었고 이 상태로 softmax classifier를 써봤자 성능이 50.9% 정도였다.
- 반면, positive와 negative 기준을 hard (IoU < 0.3)하게 잡고 SVM을 학습한 경우 54.2%로 mAP의 큰 상승이 보였다.
- 실제로 negative sample의 threshold가 되는 IoU 0.1, 0.2, 0.3, 0.4, 0.5에 대해 모두 테스해봤을 때 성능에 굉장히 민감했고 0.3일 때가 가장 높았다고 한다.
Result
-
PASCAL VOC datasset

- 기존 알고리즘보다 최소 13% 이상의 mAP 상승을 보이며 특히 동일한 selective search를 사용하는 UVA, Regionlets보다 크게 향상.
- Bound box regression 사용 시 성능이 향상.

- 앞서 보았듯이 DPM 보다 성능이 좋다.
- Fine-tuning과 Bound box regression은 성능 향상에 중요한 요소.
- Parameter의 개수가 많다고 꼭 성능 향상이 되진 않는다.(아무래도 data insufficiency가 원인이겠다고 생각)

- 더 큰 CNN model인 VGGNet 16 사용시 성능 향상 (R-CNN with O-Net)
-
ILSVRC 2013 dataset

- ILSVRC는 class가 200개인데 이 때도 R-CNN with BB의 성능이 그 외의 알고리즘을 능가.
-
Error Analysis

- False Positive type 중에 가장 자주 큰 부분은 poor localization 때문이며 이를 개선하기 위한 Bounding box regression은 효과가 있었다.
Conclusion
- Region Proposal + CNN with fine-tuning으로 object detection 성능을 크게 올렸다.
My thoughts
- 한 분야의 breakthrough를 만들어내는 논문을 읽을 때면 항상 존경심이 든다.
- CNN을 object detection에 이식시켜 훌륭한 성능 향상을 이뤄냈다. Two-stage object detector의 시초이다.
- 한계점은 다음과 같다.
- Computation time ; Selective search로 2000개의 region proposal을 뽑아내며 그리고 이 region 모두를 forward propagation하기 때문에 inference에 오래걸릴 수 밖에 없다.
- Distortion due to warping ; 아무래도 임의로 image를 warp하는 과정에 input이 왜곡된다.
- Multi-stage training ; CNN, SVM, Bounding box regression 이렇게 3개의 모델을 따로 학습해야한다.
- 다음 포스트에서는 R-CNN 이후의 개선된 two-stage object detection 알고리즘을 살펴보겠다.
댓글남기기